
The Raspberry Pi, a small yet powerful device, has become increasingly popular for various computing projects, including running large language models (LLMs) like Llama. This blog post provides a detailed guide on setting up your Raspberry Pi, installing Llama, configuring it, and troubleshooting common issues.
Setting Up Your Raspberry Pi
- Flashing the OS: Begin by downloading the Raspberry Pi Imager from the official Raspberry Pi website. Select the appropriate OS. I used Raspbian OS since it's pretty tiny and neat. Flash the OS to a micro SD card.
- Initial Configuration: Insert the microSD card into your Raspberry Pi and boot up the device. You might want to use an external monitor and devices to be able to do the initial setup.
Brining LLama to your Pi
Llama (Large Language Model Meta AI) is a family of autoregressive large language models (LLMs), released by Meta AI starting in February 2023.
Install Git: Open a terminal and ensure that git is installed:
sudo apt update && sudo apt install git
Install Python modules that will work with the model to create a chatbot:
pip install torch numpy sentencepiece
Ensure that you have g++ and build-essential installed, as these are needed to build C applications:
sudo apt install g++ build-essential
Cloning the Repository - LLama.cpp
The main goal of llama.cpp is to enable LLM inference with minimal setup and state-of-the-art performance on a wide variety of hardware - locally and in the cloud.
git clone https://github.com/ggerganov/llama.cpp
Build the project
cd llama.cpp
make
Wait for the build to complete while you can get a model downloaded
Since Raspberry Pi is a small device, it's wise to get a tiny model and hence we will go with Tiny LLM.
Download any one of the version from here
I used tinyllama-1.1b-chat-v1.0.Q6_K.gguf
Go to /models folder inside llama.cpp and run below command in terminal to download the model
wget https://huggingface.co/TheBloke/TinyLlama-1.1B-Chat-v1.0-GGUF/resolve/main/tinyllama-1.1b-chat-v1.0.Q6_K.gguf
Running your model
Hopefully, the make command would have your app setup. Now all you need to do is run the server -
./server -m models/tinyllama-1.1b-chat-v1.0.Q6_K.gguf -t 3
You should now see the llama.cpp server up -
Go to localhost:8080, you should see the below UI
Let's try playing with the model now.
Ask a quick question and see it respond 😃
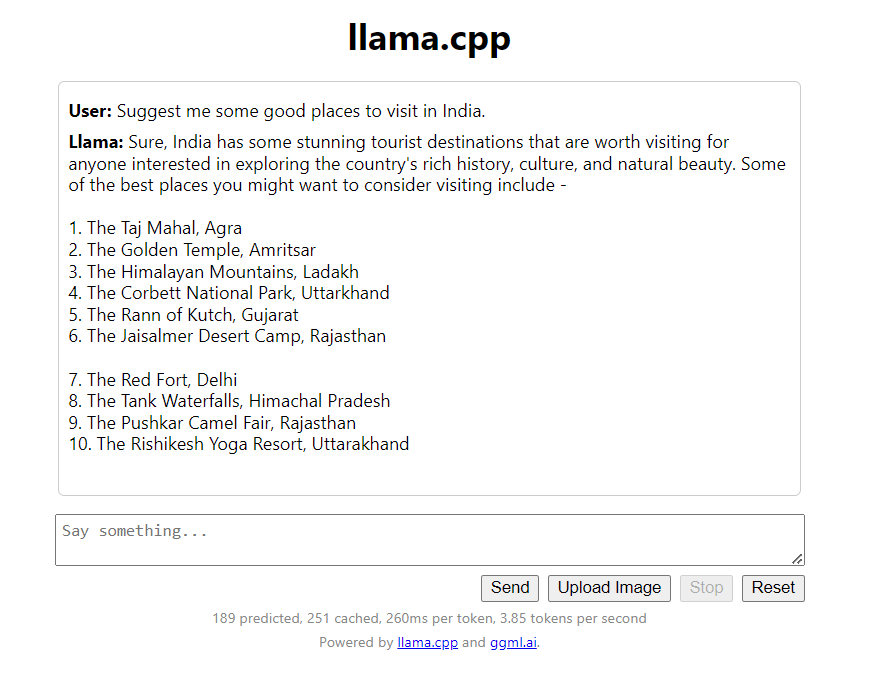
Hey! It just suggested some great places to visit in India!
Do give it a try. It's amazing !! 🥂
