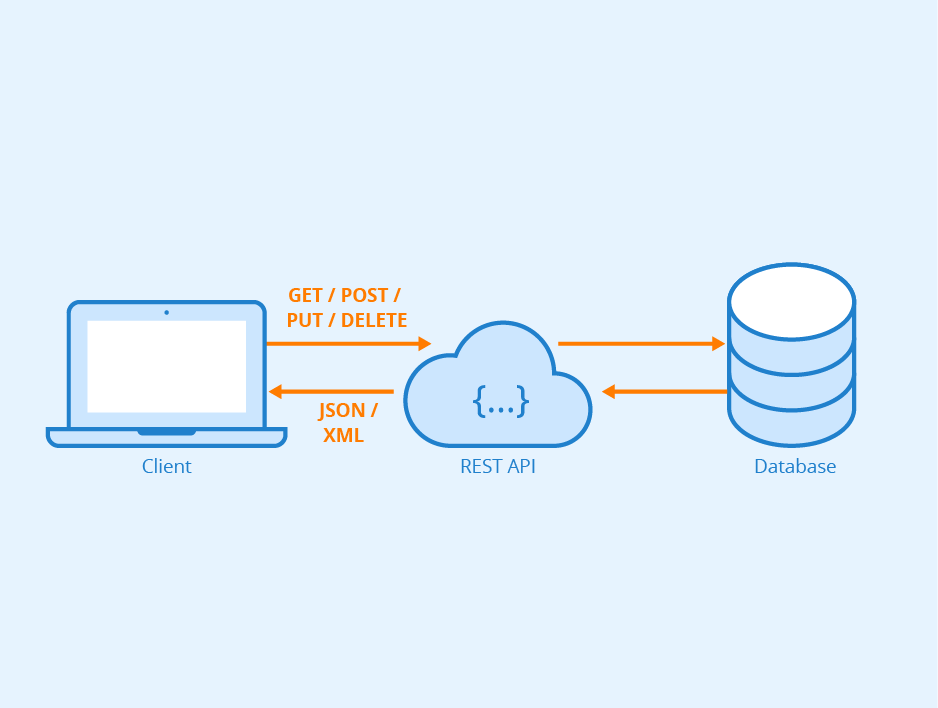
When designing a REST API (or attempting to follow this pattern), we always overlook the importance of establishing a tidy, readable, and scalable architecture, but this has a huge effect in the long run as the application develops.
1. Use HTTP Verbs the right way
REST API encourages us to use an HTTP method for each of the application’s CRUD actions. A few of the HTTP Verbs available are: GET, POST, PUT, DELETE, and PATCH. The name of the endpoint associated with the resource must be accompanied by the HTTP verb related to the applied action.
I often find people using endpoint naming conventions as:
- GET: /get_users ❌
- POST: /create_users ❌
But, the verb itself signifies action. So prefixing actions is not a good practice.
Better naming of the APIs would be:
- GET: /users ✔
- POST: /users ✔
- PUT: /users ✔
- PATCH: /users ✔
This is a lot cleaner and better!
2. Use proper status codes
One of the most important features of a REST API is that the status codes returned are related. This means that whether our outcome is acceptable or not, we can relate the message we want to express in a more descriptive way.
For example, a status 200, immediately gives a notion of success while 400 or 500 gives an idea of failure.
Returning the wrong status code is malpractice and should be avoided.
Here are some status codes that are frequently used.

3. Add filter, pagination, and sort capability
Many applications that use our API will choose to use fewer resources from our service in some way, either because of efficiency, a search system, or because the information is unnecessary, or simply because they want to display something specific from our resources.
Filter, sort, and pagination, in addition to expanding the functionalities of our API, help us reduce the consumption of resources on our server.
Let's suppose for a given search query there are hundreds and thousands of records. Responding to the full list in one go would be a headache for both the server and the client.
Therefore, we should have the capability to limit the response message.
Some examples:
- Filtering users based on employee type and age
GET /users?type=permanent&age=25 - Paginate and return 20rows starting from 0th row
GET /users?limit=20&offset=0 - Sort users based on name ascending
We can use +<field_name> to denote ascending and -<field_name> to denote descending sort order.
GET /users?sort=+name
4. Endpoint naming and Plural endpoints
We often have this dilemma on whether to use singular or plural endpoints. Personally, I prefer plural since we can pass URI Parameters to a plural endpoint to get singular records.
Example:
- GET: /users
- Brings all users(plural)
- GET: /users/:id
- Brings a particular user matching the id(singular)
Also, while naming endpoints make sure to give proper names.
We would want the endpoint to be named users if it's returning user data and not dog or cat or something else. The endpoint name should be mnemonic.
5. Resource hierarchy
What if we want to access a closely linked entity that belongs to a resource?
To show this relationship we have two options:
- Hierarchically append the article to our author's endpoint
- Query string
Let’s take the classic example of authors and books.
The two options will look like below:
- GET /authors/shakespeare/book/hamlet
- GET /books?author=shakespeare&name=hamlet
I prefer query string since it adds more insight into the filtering conditions.
6. Versioning
Change is the only permanent thing in this universe. Once you have that API in production and people are using it, it is inevitable that there will be bug fixes, changes, and new endpoints added.
Now, let's say our clients have started using the API and we plan to make some major changes that can break some of the way the client uses our API. This is where we need proper versioning of APIs.
The client will still use version V1 while we make changes in version V2. Now we support both and the client can choose to change to V2 eventually.
There are several ways, but I am a fan of the versioned URI, in which we will explicitly have the version of our route in our endpoint.
- GET /v1/users
- GET /v2/users
Adding a version in URI makes it more clean and mnemonic.
7. Caching
Caching is one of the most effective methods for improving an API's speed and resource use. The concept is to avoid asking the database for the same request several times if the outcome remains the same.
There are many caching options available, like Redis, Memcache, etc.
For AWS-based we can also consider S3, and Elasticache as some means of caching data.
One major concern with caching is how long we cache. This has been debated since the beginning and there is no one foolproof solution to this. One way to deal would be to divide your endpoints into two types, static and dynamic.
Caching static data wouldn't be a problem but for data that is dynamic, we might have to be a bit more careful.
8. Documentation
Probably the most important step to bring value to your hard work. Developing API is something but making it's documentation good enough for users to use is a separate game altogether.
Tools like MuleSoft have RAML for modelling which gives documentation out of the box.
We can also go for other formats as well like Open API specification which will make your API documentation look better.
We document API mainly for the following reasons:
- Accessibility: One of the most important qualities of the interface is its location and usability, and we do not want to provide customers with a 120-page document on how to use the API. The most realistic thing we can do is place our documents on the cloud, so everybody can see them.
- Responses and Requests: The information we provide has to contemplate all the possible results that any resource may produce and how to consume them. This can additionally have SDKs for various popular programming languages.
- Examples: It is very important to provide examples of the requests and responses to make sure our clients know what is needed from them and what they can expect.
API is the best thing in the current world which allows systems to integrate and interact in a seamless manner. Being a good API developer it's our duty to make people love API and these practices can definitely help you do so!
Hope you liked it. Cheers!



